
[2023阿里云CTF]ezBean复现及相关fastjson机制深入分析
[2023阿里云CTF]ezBean复现及相关fastjson机制深入分析
tip:环境为JDK1.8
本篇文章会讲到:
1.[2023阿里云CTF]ezBean的题目解答
2.fastjson的getter机制深入分析
3.如何利用fastjson与objectInputStream的差异化来绕过黑名单检测机制
ezbean
下载源码,看控制器,只有一个路由/read,接受BASE64编码过的序列化流进行反序列化
1 |
|
JAVA反序列化题,先看依赖库,发现有1.2.60版本的fastjson
但是不能直接把payload打进去,因为在反序列化的时候resolveClass方法会检测黑名单


所以还是根据题目环境制定策略
去看MyBean类,发现有getConnect方法,还有JMXConnector成员,并且getConnect方法中会调用JMX的connect方法
去看这个JMX的源码,发现是一个接口,并且是由RMIConnector实现
这里说一下JMX和RMI的关系:
JMX 是 Java 的一种技术和标准,它用于监控和管理 Java 应用程序、对象、设备和服务。JMX 的主要部分是 MBean (Managed Bean),它是一种特殊的 JavaBean,包含了一些用于远程管理的接口。
RMI 是 Java 的一种技术,允许在 JVM 之间进行远程方法调用。这意味着在一个 JVM 中运行的对象可以调用另一个 JVM 中运行的对象的方法,就像它们在同一个 JVM 中一样。
JMX 和 RMI 的关系体现在,JMX 使用 RMI 作为其默认的远程传输协议,可以在网络上的不同 JVM 之间进行通信。
JMXConnector 是一个接口,它定义了客户端如何连接到 JMX 服务的方法。这些方法中包括 connect()
RMIConnector 是 JMXConnector的一个实现,它使用 RMI 协议来进行网络通信。这意味着,当你使用
RMIConnector创建一个连接时,你实际上是在使用 RMI 协议连接到 JMX 服务。
所以这里我们的思路就出来了,想办法使得服务端反序列化我们的payload之后,能够调用RMI远程连接到我们的vps上进行利用
达到这个目标需要两个条件:
1.目标服务端调用getConnect
2.控制JMX对象使其rmi连接到我们的vps的恶意rmi
为了达到这两个目标,最终POC如下(此POC源自:杭师大网安的WP)
1 | import com.alibaba.fastjson.JSONArray; |
分析一下POC:
首先构造JMXConnector对象,实现类为RMIConnector,构造函数需要一个JMXServiceURL,这里我们提前开一个恶意RMI服务

我们需要构造MyBean,但面临两个安全限制
1.fastjson默认禁用autotype,也就是说不能反序列化带有类型@type的信息,也就是对象
2.resolveClass禁用了java.rmi包,无法直接反序列化MyBean(这里对mybean的正则匹配的是com.ctf…..(后面任意数量的点,所以mybean不受影响))
对于第一点:因为之前没接触过fastjson,所以autotype机制没有了解过,于是各种调试跟踪,发现个很奇怪的点,就是autotype默认应该是关闭的,但在Parser.class中,决定autotype是否开启的autoTypeSupport却在逻辑运算后为true,那么这个默认关闭的autotype又有什么意义呢?(有师傅懂得话希望得到解答^-^)
2
3
4
5
6
7
8
9
//Parser.class
boolean autoTypeSupport = this.autoTypeSupport || (features & mask) != 0 || (JSON.DEFAULT_PARSER_FEATURE & mask) != 0;//这里autoTypeSupport在执行时会设置为true
if (clazz == null && (autoTypeSupport || jsonType || expectClassFlag)) {
boolean cacheClass = autoTypeSupport || jsonType;
clazz = TypeUtils.loadClass(typeName, this.defaultClassLoader, cacheClass);
}
对于第二点绕过,就是把黑名单类往json里扔,原理可以用一张报错的堆栈图说明

题目设置的黑名单只针对ObjectInputStream,而我们把RMIconnetor类扔到fastjson后,fastjson会接过这个反序列化的任务,而题目并没有针对fastjson的反序列化进行黑名单检测,所以成功绕过
然后是
1 | BadAttributeValueExpException val =new BadAttributeValueExpException(null); |
这段是一个java反序列化攻击常用的一个类,因为这个类在反序列化时会自动调用一个名为val的私有成员的toString方法

这里把val设置成存储了构造好的MyBean对象的JSONArray对象,所以当反序列化时会自动调压JSONArray的toString方法
跟进JSONArray源码,其父类JSON有toString方法,调用toJSONString
1 | public String toJSONString() { |
(new JSONSerializer(out)).write(this)会根据对象的类型返回合适的序列化器,之后会使用这个序列化器将JSON里的存储的对象序列化为JSON字符串,这里我们打断点调试,可以看出,fastjson为我们选择的是ListSerializer(因为需要序列化的是JSONArray,是List类型)
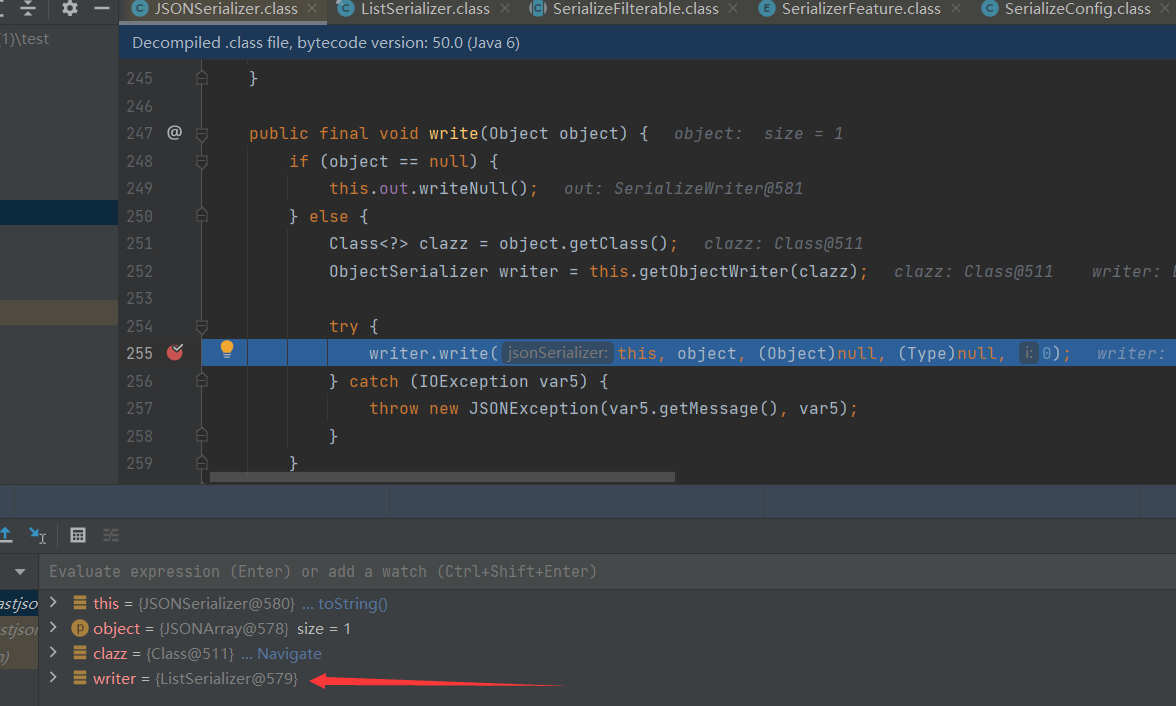
跟进ListSerializer的write方法,
其中这一块
1 | try { |
serializer.getObjectWriter是根据JSONArray的每一个元素选择不同的序列化器
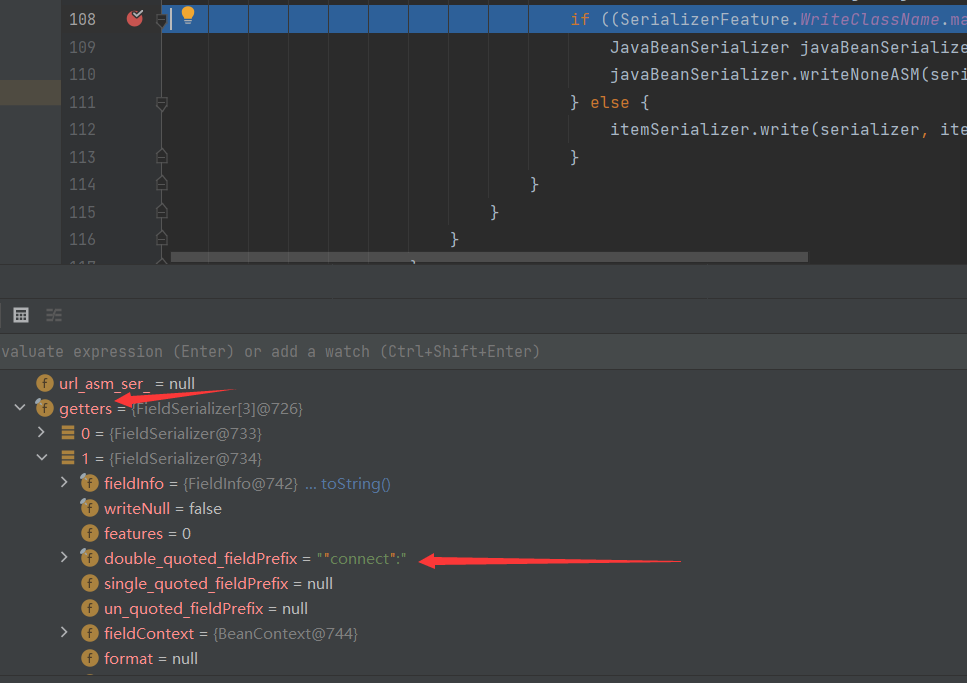
慢慢调试,可以看到这里给我们选择的是ASMSerializer序列化器,并且已经获取到了MyBean对象的所有getter,这里是一个非常关键的地方,就是序列化器会获取对象所有的以getXxxxx这种格式的方法,即使它不是一个真正的getter,但只要符合这种命名规范的方法都会被序列化器认为是getter
我们可以在MyBean里加一个方法来试验一下
1 | public Object getConnect(){ |
然后调试,可以看到即使不存在一个connect变量,但依然被认定这个方法是一个名为connect成员的getter
接着用ASM序列化器对MyBean进行序列化,但由于ASM序列化器是运行时动态生成的,所以我们无法看到源码,但是这个ASM序列化器是由ASMSerializerFactory类中的方法动态生成的,具体可以参考ASMSerializerFactory的源码。这个工厂类中的
createJavaBeanSerializer()方法使用了ASM库来动态生成JavaBeanSerializer
也就是说,ASM序列化器是用ASM字节码技术动态生成的一系列序列化器,本质是在JavaBeanSerializer的基础上进行了改进,所以核心功能和JavaBeanSerializer其实差不多,为了解释清楚基本原理,我们就跟进JavaBeanSerializer,并且对于一般java对象,默认使用的是JavaBeanSerializer
JavaBeanSerializer在序列化Java对象时,会遍历并调用对象的getter方法。这个过程主要在JavaBeanSerializer的构造函数以及getFieldValuesMap方法中实现。
跟进JavaBeanSerializer,分析一下
首先,依次通过三个构造函数来构建一个beanInfo,最后一个构造函数对beanInfo进行处理
1 | public JavaBeanSerializer(Class<?> beanType) { |
beanInfo是SerializeBeanInfo类型的对象,它保存了有关Java Bean(在这里为MyBean)的所有信息,包括类的结构、属性、getter和setter方法等。这些信息在创建
JavaBeanSerializer时被收集并保存在beanInfo对象中,以便在后续的序列化过程中使用。
1 | this.sortedGetters = new FieldSerializer[beanInfo.sortedFields.length]; |
这个代码创建了一一系列FieldSerializer对象,每个对象代表一个bean字段,
跟进FieldSerializer
getPropertyValueDirect方法会对每一个字段调用对应的getter
1 | public Object getPropertyValueDirect(Object object) throws InvocationTargetException, IllegalAccessException { |
this.fieldInfo.get方法调用了getter
继续跟进FieldInfo类,

最终在这里通过反射调用了对应字段的getter方法,也就实现了触发getConnect(),至此两个目标都达成了,
分析完后,最终发送生成的payload(要发送三次),这里我本地演示弹出calc

最终执行过程:
1 | objectInputStream.readObject()->BadAttributeValueExpException.readObject()->JSON.toString()->toJSONString()->new JSONSerializer(out)).write(this)->ListSerializer.write->itemSerializer.write(serializer, item, i, elementType, features)->ASMSerilizer遍历每个成员并调用getter->getConnect()->RMIconnector->连接恶意rmi服务->执行恶意代码 |
思考:
举一反三:
虽然MyBean类并没有被过滤,但由于我们需要调用其getConnect方法,需要借助JSON的getter机制,所以还是将mybean扔进json中,但对于RMIConnector,为了绕过黑名单,还是需要扔进JSON,这就是题目给出fastjson的目的吧
为什么要发送三次?
这篇文章写了2天,其中花了一天时间都在研究这个问题….
通过不断的调试,本人算是大概摸到了一点门道,但不一定完全正确
fastjson为了提高反序列化效率,在进行反序列化的时候会有一张map,这张map存储的是基本java类,充当一个缓存作用(这也说明了为什么基本数据类型都可以直接反序列化,因为这map中都存了这些类)
1 | //ParserConfig.class |
因此,当fastjson准备反序列化一个对象的时候,会先判断这个类是否在map表中,如果是,则直接反序列化;
否则,将这个类加入到map表,然后判断这个类是否存在无参构造函数,这是因为fastjson在反序列化当中构建一个对象时,会先获取其默认(无参)构造函数来构建一个对象,然后再使用setter来进行字段填充,而RMIConnector和JMXServiceURL都没有无参构造函数,所以会发生报错
1 | //ParserConfig.class |
1 | if (paramNames == null || types.length != paramNames.length) { |

但是为什么在第三次发送时就成功了呢?
这是因为,fastjson是先将类存到map中,然后再执行无参构造的判断,所以我们这三次的效果分别就是:
1.将RMIConnector存入map,这样下次直接就可以反序列化而不必再进行无参构造的判断
2.将JMXService存入map,目的同上
3.所有用到的类均已存入map,执行反序列化成功